“Fault tolerance is no longer an option but a necessity,” states Franck Cappello, project manager of research on resilience at the extreme scale at Argonne National Laboratory. “And the ability to reliably predict failures can significantly reduce the overhead of fault-tolerance strategies and the recovery cost.”
In a special issue article in the International Journal of High Performance Computing Applications, Cappello and his colleagues at Argonne and the University of Illinois at Urbana-Champaign (UIUC) discuss issues in failure prediction and present a new hybrid approach to overcome the limitations of current models.
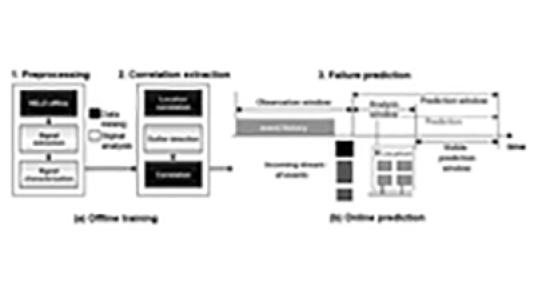
One popular way of building prediction models is to analyze log files, which provide information about many components in the system. In general, data-mining algorithms are used to automate the process: grouping the messages into categories, filtering redundant events, extracting correlations between events, and using the correlations to predict future failures. The problem with the approach is that each step introduces imprecision, or noise, that influences the accuracy of the prediction.
To decrease this noise and enable failure prediction on real production systems, the UIUC/Argonne research team has developed a hybrid methodology that combines the advantages of existing data-mining techniques with a signal analysis approach.
“Data mining is an efficient method for extracting patterns and for developing accurate correlations between behaviors and modules. But current data-mining algorithms apply the same extraction methods on all data entries. We believe that different failures have different distributions and create different symptoms in the system,” said Marc Snir, director the Mathematics and Computer Science Division at Argonne and one of the developers of the new methodology.
One advantage of using signal analysis is that it eliminates the filtering process required by pure data-mining approaches. The signals compress the data in the log in a natural way without losing any occurrences that might be useful to the prediction. Different signal analysis techniques are used to distinguish the different distributions of events and to study how failures affect each. “We regard this as a key step,” said Ana Gainaru, the Ph.D. student at UIUC developing this new approach.
Deciding when to trigger a prediction is also critical. What value should be used when deciding whether a correlation is strong? How often should the correlations data be updated? To answer these questions, the researchers used data to predict the next nine months of Blue Gene/L. By adapting the correlations and signal characterization over time, they were able to keep the recall value almost constant. The experiments showed, however, that while 50% of the error occurrences were predicted with a high precision (90%), there was an uneven distribution between different components. The researchers plan to study the components of the system individually in order to better understand what influences the prediction process for each of them. Other plans include inspecting different fault-avoidance protocols and computing the actual benefit when running large-scale applications in production.
Details about this research can be found in the paper “Failure prediction of HPC systems and applications: Current situation and open issues,” A. Gainaru, F. Cappello, M. Snir, and W. Kramer, International Journal of High Performance Computing Applications, 27(3) 273-282, 2013.