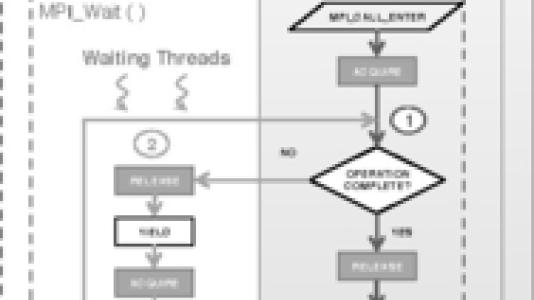
In computer science, the term is used somewhat similarly. Contention arises, for example, when threads, or running tasks, compete for scarce resources, a situation that is becoming increasingly prevalent on extreme-scale computer architectures. One solution is the use of locks to synchronize accesses. MPI implementations typically rely on locking mechanisms to ensure thread safety in applications requiring concurrent multithreaded access. But optimal lock synchronization is problematic, depending on several variables such as the length of the critical section, lock hand-over costs, and fairness and load-balancing issues.
A team of researchers at Argonne National Laboratory, the Chinese Academy of Sciences, Intel, and the Tokyo Institute of Technology now have devised an approach that uses arbitration to favor execution paths that contribute better to the overall progress.
“Previous works have focused principally on techniques to improve lock scalability and synchronization granularity, with little research conducted on the role of arbitration in improving the progress of a concurrent system,” said Abdelhalim Amer, a postdoctoral appointee in Argonne’s Mathematics and Computer Science Division. “Our idea is to bias the arbitration to favor progress.”
Biasing might sound unfair, but a comparison with other approaches commonly used in MPI implementations shows that it achieves better results. For example, using the Pthread mutex approach provided on many HPC systems offers the benefits of ease of use, portability, and efficiency in uncontested cases; but in contested cases, it can lead to unbounded lock monopolization, resulting in unnecessary network polling and wasted lock acquisitions while other threads could have been performing work.
Introducing fairness by using first-in, first-out (FIFO) arbitration can break the lock monopolization, circulating the lock among contending threads. Results show that FIFO locks, such as ticket and CLH, conduct far less wasted lock acquisitions and better communication progress properties than the Pthread mutex does. To further improve progress and reduce waste, however, an adaptive lock was necessary: one that reduced the interference stemming from waiting threads by promoting threads with a higher work potential.
To this end, Amer and his colleagues devised a two-level priority lock. The first lock is meant for low-priority execution paths. The second lock acts as a wall to block low-priority threads when high-priority threads are present. Such priority locking is helpful when a large number of operations need to be issued. Results show improvements of 50–100% compared with the Pthread mutex.
Nevertheless, the research team acknowledged that the situation is complicated. In some cases, prioritizing the main path had little effect because most of the time threads are waiting in the progress loop. Similarly, in tests on a Graph500 benchmark, the priority lock approach showed no advantage, because all threads always had the same high priority inside the runtime. On the other hand, in tests of a stencil kernel – a class of iterative methods found in many scientific and engineering applications – priority locking performed better than the other locks.
Several additional factors also need to be considered. For example, an MPI runtime is sensitive to the number of queued requests, apparently because the associated internal data structures are proportional. A related issue involves the order in which threads acquire resources: this can affect the data locality of MPI internal structures as well as application data and hence the cache performance.
The researchers have already begun considering ways that might enhance the performance. Most of their previous work on arbitration ignored the granularity in a critical region. But a possible avenue of study might be to start with a global critical section, explore effective arbitration methods, reduce the granularity if high contention persists, and repeat the process.
“We believe that combining the arbitration approaches will have a synergistic effect on reducing the runtime contention,” said Amer. “We hope that our studies will also guide the development of other thread-safe libraries.”
For more information, see the paper
Abdelhallim Amer, Huiwei Lu, Yanjie Wei, Jeff Hammond, Satoshi Matsuoka, and Pavan Balaji, Locking aspects in multithreaded MPI implementations, MCS-P6005-0516.